
I built a research engine on Zo.
The first post I wrote on top of it hit 196k impressions.

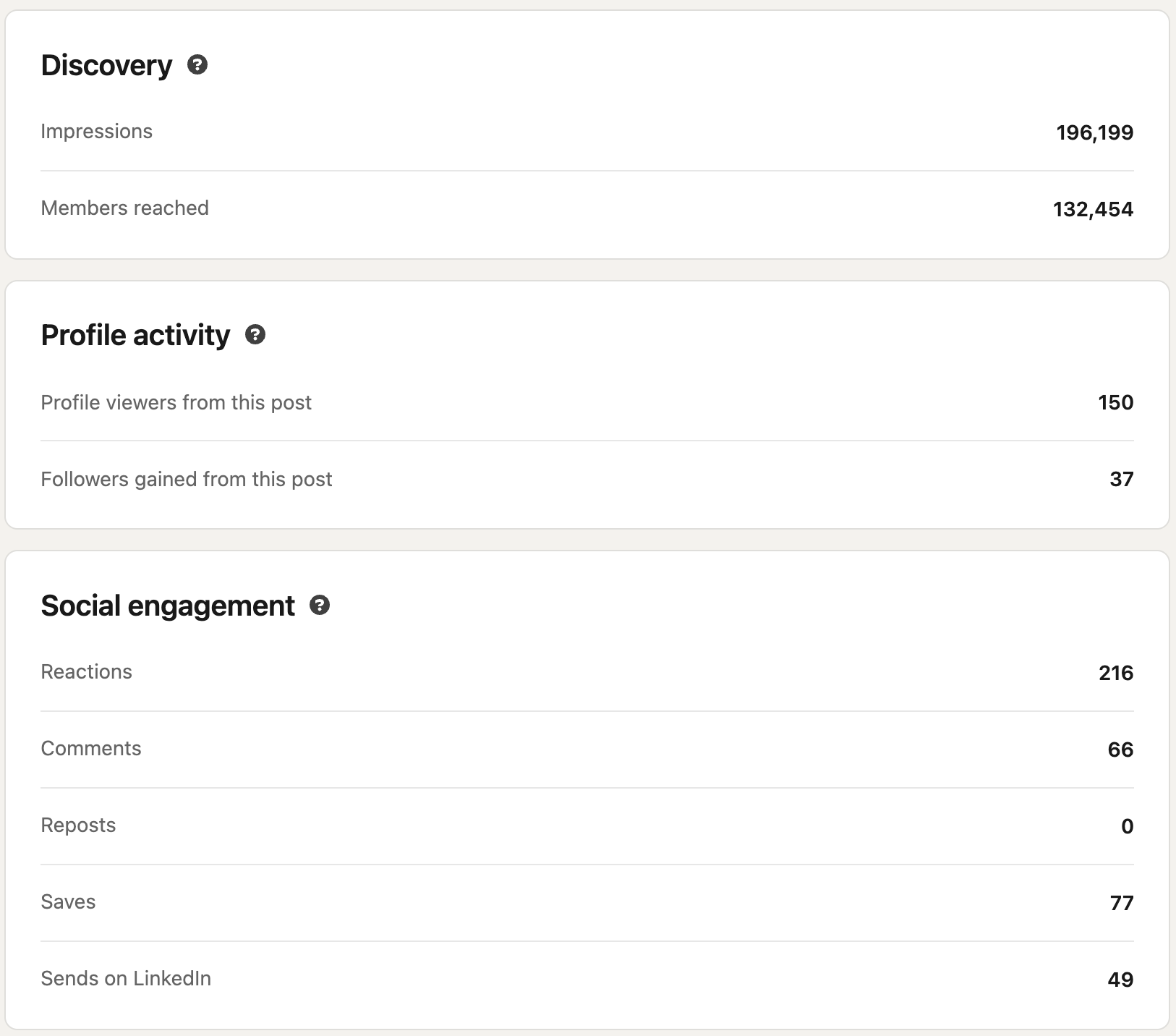
196,000 impressions. 77 saves. 49 sends. 37 new followers. One LinkedIn post.
The post was about Jorge Costa, a public sector account exec at ServiceNow who closed $27M in federal deals, was owed $380,987 in commissions on his own comp plan, and was paid none of it. He’s still at ServiceNow and now suing them for double damages. The Register filed the story on 31 March.
The post landed because of what sits underneath it. Over the last couple of weeks I’ve built a research engine on my Zo computer. It found the Jorge Costa story in my reading queue, pulled the underlying court filing as a primary source, ran the structural argument against six Reddit threads across r/techsales, r/sales, and r/CustomerSuccess for ground-level reaction, and surfaced quotes from real reps with attribution. By the time I sat down to write, the dossier was already on my screen. Sources verified. Quotes attributed. The structural argument pressure-tested against the audience that would actually read it.
This is the post about that engine and how I built it.
I used Zo to build a research engine for my LinkedIn and paid Substack content. A persona called Eve, a folder I drop links into during the week, and a six-pass workflow that pulls primary sources, verifies them against the underlying news or court filings, runs the angle against Reddit for audience reaction, and hands me a dossier I can write on top of.
Last week the engine produced the dossier behind the highest-performing LinkedIn post I’ve shipped. 196,000 impressions, 77 saves, 49 sends, and 37 new followers from a single post. The engine ran the research; I wrote the post on top of it.
The trap
Most AI content tools produce slop. A single prompt in, a fluent-sounding paragraph out, and the kind of vague industry-insight phrasing that gets scrolled past in two seconds. The audience reads enough of it on LinkedIn to recognise the shape, and the model’s output dies on the feed.
The reason is the workflow around the model. Most content tools wrap a single API call in a UI and call it a product. No folder of voice samples to calibrate against. No primary-source verification. No cross-check against what’s already been said in the same shape on the same feed. The model is doing the only thing it knows how to do, on whatever input you give it, with no guardrails.
What makes a post land is the research underneath it. Specific numbers from real filings. Audience reactions in their own words. Quotes that can be attributed. A structural argument that hasn’t been done in the same shape on the same feed three weeks ago. The engine I built on Zo runs every one of those checks before I see anything.
What Zo and I built
I sat down with Zo and started talking the problem through. The conversation kept circling back to one question: how do I separate the research that earns a post from the writing that delivers it? Zo pushed back on every loose definition. What counts as a verified source? How does the engine know it’s not retreading the same angle I posted six weeks ago? How do I stop a Reddit paraphrase from entering the dossier as if it were a primary fact? By the end of the conversation we’d worked the problem down to a six-pass workflow that runs on a single folder of inputs.
Here’s the brief Zo and I worked out together, copy-pasteable if you want to do the same on your own Zo:
Build me a research engine for my LinkedIn and Substack content.
Inputs:
- A folder called incoming/ where I drop links during the week:
Reddit threads, news articles, LinkedIn posts, Substack pieces.
- A folder called voice-samples/ with my best-performing past
posts as voice anchors.
- A folder called published/ with everything I've already shipped,
including a titles-already-used.md file as the "don't repeat" list.
The engine runs in six passes:
(1) Source consumption. Read every link in incoming/ in full.
(2) Reddit-required search. At least three subreddits, four to
six threads pulled in full with direct quotes and usernames.
The audience talks honestly there. Vendor blogs are SEO.
Reddit is lived experience.
(3) Primary-source verification. Every news event, lawsuit, or
company action gets verified against the underlying article
or filing. Reddit can flag the story; it cannot be the source.
(4) Structural-similarity check. Cross-reference the candidate
angle against published/ titles. If it pattern-matches a post
I shipped in the last six months, flag it before drafting.
(5) Voice calibration. The proposed structure has to map to a
specific anchor in voice-samples/. Same hook shape, same
rhythm, same close energy.
(6) Self-check. Sources verified, quotes attributed, voice anchor
named, no contrast patterns or em-dashes anywhere in the
suggested draft.
Output: one timestamped dossier in research-dossiers/, then a
LinkedIn post and a long-form draft in drafts-ready/.Zo built the persona, wired the folder structure, and ran the first dossier the same week. The persona is called Eve. The platform underneath her is doing the heavy lifting. Zo Rules force her to verify a source before she asserts a fact. The audit log catches the runs where research stalls and produces nothing. SOUL.md keeps her voice and behaviour consistent across every cycle, even when the model running her changes underneath. None of those primitives exist on a single-prompt content tool.
The first cycle exposed weaknesses the second cycle fixed. Eve paraphrased a number loosely from a Reddit thread on the first paid post; the rule forcing primary-source verification on every news anchor was written into her spec that same afternoon as a correction.
What changed
The first dossier the engine produced was on Jorge Costa. The court filing on the lawsuit was pulled. Seven Reddit usernames had been quoted in full with attribution: CyberStartupGuy, wyrd_smyth, speed32, almarcuse, EntrancePrevious5687, ActionJ2614, and ThriceHawk. The structural argument about how comp plans are designed to leave the majority of reps short of OTE was already drafted, with the supporting quotes mapped under each beat.
I wrote the LinkedIn version on top of that. Hook line, three escalating numbers, a specific named person, an authority injection from The Register, and a single closing line that drove to the link in the comments. I ran the post through the humanizer and shipped it on the Thursday morning.
Five days later it was at 196,000 impressions, 77 saves, 49 sends, and 37 new followers. The 77 saves are the number that matters most. Saves are what people do with content they trust enough to revisit. The post earned its save count because the research underneath it had been done before any sentence was written, and Eve’s rules are what got the research done.

Takeaway
The bottleneck on great content is the research that earns the writing. The engine I built on Zo runs the research before I sit down. The writing gets to start with everything verified, quoted, and pressure-tested. The 196,000 impressions are the receipt. The next dossier is already sitting in research-dossiers/, waiting for an evening I have free.
Interested in trying out Zo? You can get going here: https://zo-computer.cello.so/26ku7DZEc3O